We denote the true (actual) value of action a as , and the estimated value on the -th time step as .
Action-Value methods
These approaches are repeatedly selecting an action and estimating their value.
value estimate
Sample average
We perform exploration and for every distinct action , which was chosen times. If individual rewards of the action are , where , the average reward is estimated as
Due to the Law of large numbers, converges to .
To decrease memory requirement, we can only store and . The incremental average can be derived iteratively as
Weighted sample average
variant of this incremental sum, where recent actions have larger impact than the old ones, can have a constant step-size parameter . This changes the formula to
- weight decays exponentially for the constant, sometimes it is called exponential, recency-weighted average.
- it is suitable for non-stationary problems, where environment(the bandit) changes.
Step size results in basic sample average, which doesn’t decay and is more suitable for stationary bandits. Robbins-Monro theorem can be used to determine, whether the sequence with step-size converges to truth value by satisfying following conditions
Non-convergance is not bad, it simply means that the the action value won’t stop changing. That is desirable for non-stationary problems.
action selecting
Greedy approach always selects the action with greatest value. Action selected at the step is given by
This approach always exploits.
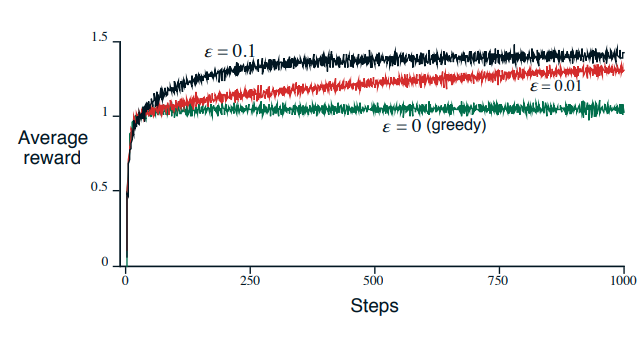
-greedy approach has probability to explore, instead of exploit. As , each action is sampled infinitely often, the convergence of is guaranteed if the sequence converges. Probability of selecting greedy action is at least .