SSU | [Metoda podpůrných vektorů]
Reformulation of the Maximum margin classifier problem into a quadratic program solving
subject to
Support vectors are the training examples that are closest to the decision hyperplane. These are the only training data we need to keep after training is finished.
Question
Draw a line and a point. Draw a triangle with a right angle and write what the distances are equal to between the line and the point. What is the distance from the margin to other points?
Answer
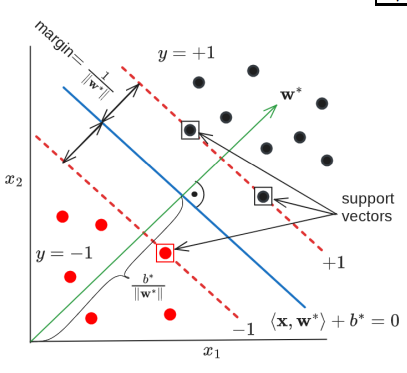
Question
Why does minimizing the weight vector maximizes the margin? What is left to minimize when the closest point has distance of 1?
Answer
When the distance , the distance from the decision bound to the support vector is just .
Soft-margin SVM
When data are not linearly separable, we can introduce slack-variables and reformulate the quadratic program to
subject to
Slack variable is equal to 0, when point with index is classified correctly and is positive when misclassified. It “pushes” the point further away from the decision bound, so the point ends up correctly classified.
Regularization constant is a hyperparameter. Setting it high pushes slack variables close to zero and tends to overfitting. Setting it low allows greater margin, smoother bound and better generalization.
Implicit structured risk minimization
Structural risk minimization is implemented directly inside the algorithm. We can re-define the objective function with Hinge loss as
- Hinge loss is exactly equal to the slack variables.
- It also implicitly satisfies the conditions that margin is at least 1.
Parameter becomes the complexity term.